Deep Learningで遊びながらアイドルの顔診断器を作る #juicejuice
最後にブログを書いてから1ヶ月が経ってしまいました。この期間の振り返りもしたいところですが、それはまた別の機会に。
今回はこの2週間くらいDeep Learningを使って画像を分類したりする遊びをしていましたのでそれについて。
まずは成果物から。

画像をアップするとJuice=Juiceというハロプロのアイドルにどれだけ似てる顔なのかを判定できるサイトです(herokuの無料枠で動いてるのでサーバーはいともカンタンに死にます...😇)。
見せられるようなコードではないですが、一応ソースコードも置いておきます。
- GitHub - YuheiNakasaka/yukanya: Juice=Juiceのメンバーを画像から判定する分類器
- GitHub - YuheiNakasaka/yukanya-api
- GitHub - YuheiNakasaka/yukanya-front
何番煎じかわからないほどにこの手の遊びは行われているのでコードやアルゴリズムの細かい解説は他の記事に譲ります。
以下ではどのように作りあげていったかについてその思考過程と試行錯誤したポイントを中心に書いていきます。
画像収集
まずは学習データが必要なので画像を収集します。
先にも書きましたが対象の画像にはJuice=Juiceというハロプロのアイドルを選びました。理由は単純に好きだからです。
後々やっていくことになりますが、初心者が分類タスクに取り組む上で一番しんどいのは画像収集とそのラベル付けになります。
なのでその作業に耐えられる対象を選ぶことが重要です。
収集元としてはブログとGoogle画像検索を利用しました。
コードはこんな↓感じになります。
https://github.com/YuheiNakasaka/yukanya/blob/master/scraping.py
ブログから画像を取得する方法もありますが、その場合はメンバーごとにフォルダへ保存しようと試みても二人で写っていたり別の人が写っていたりする写真が多いのであまり効率が良くないです。
なので一番手軽なのはGoogle画像検索です。
メンバーの名前で検索して取得した画像をメンバーごとに別フォルダに保存していきます。
そして一通り収集し終えたら次はノイズを除いていく作業です。
メンバーの名前で検索していてもブログほどではないにせよ結構間違った人の画像が含まれていたりするので地道に手作業で除いていきます。
ここは気合いです。
顔画像を切り抜く
次は顔診断を作りたいので全身画像から顔だけを切り取る作業をします。
簡単なところだとOpenCVのHaar-Like特徴を利用した顔検出機能が便利です。
ただ単純にHaar-Likeを使うだけだとちょっと斜めになった顔に対応できません。特にアイドルは自撮りをするときに顔を斜めにしがちなので結構ミスクリップが発生します。
なので次に考えつくのが画像を回転させることです。斜めになっている画像を回転させて正面を向くようにすればOpenCVのHaar-Likeでもうまく検知できるようになります。
これで一件落着かと思いきや、これにも弱点があります。それは顔を検知しすぎてしまうことです。例えば10°20°30°40°のように回転させてそれぞれに顔認識をさせていくと10°20°30°のそれぞれで顔が検知できてしまったりします。本当は10°の時の1枚で良いのに3枚分同じ顔画像が生成されてしまいます。避けられるならノイズはできるだけ減らしたいです。
そこで最終的にはface_recognitionという顔認識ライブラリを使いました。dlibという機械学習ライブラリをベースにしているらしく、斜めでもボケていてもかなりの精度で顔を認識してくれます。
これを使って収集した画像から顔をクリップしてメンバーごとに保存します。
適当なCNNによるアプローチ
まずはCNNで顔画像を分類できるようにして、未知の画像に対してメンバーの誰に似ているかを診断しようという作戦です。
先の顔画像を使ってまずは適当にCNNのモデルを構築して訓練しました。
モデルの構築にはKerasを使っています。
ところで余談なのですが、2~3年くらい前に初めてDeep Learningで遊んだ時はChainerを使ってやっていたんですが、今はKerasを使っている情報が多いなという印象でした。
理由はわかりませんが、確かに単純なネットワークの構築からCNN/RNNのような定番のネットワーク、そしてVGGやResNetのような一般物体認識データセットで学習済みのモデルが簡単に使えるので敷居の低さを感じます。今はDeepLearningのライブラリはどういう使い分けがなされているのか、知ってる人いたら教えてください。
話を戻します。
最初は200 epoch/総データ量: 1290/サイズ: 64x64で学習を行いました。結果は以下の通り
validation loss:0.9541133496084102 validation accuracy:0.7042801556420234
精度は約70%。全然ダメですね。
原因はデータが少ないことだと思い、水増しに手をつけました。
水増しとは元画像を回転させたりノイズを入れたりして学習データを増やす手法です。
やりすぎると過学習を引き起こしてしまうのですが、うまく使えば元データの少なさを補填してくれます。
画像を回転させたもの、フリップしたもの、それぞれに対してガウスぼかししたものコントラストを変えたものなどを生成して最終的に
40 epoch/総データ量: 13353/サイズ: 64x64で再度学習をし直した結果、
validation loss:0.349657013838289 validation accuracy:0.9005690326445044
9割くらいまで伸びました。わーいという感じでしたが、過学習しまくってるので未知の画像でうまく識別できません。
これでは使えないので別の手法を試します。
VGG19を使った転移学習を用いたアプローチ
転移学習とはすでに学習済みの優秀なモデルを利用して全結合層の部分だけ学習し直すという手法になります。すでに特徴を捉えるのに優秀になっているモデルを使うことで特徴抽出のところをチートしちゃおうという感じです。
今回はVGG19というモデルを使って転移学習を行いました。
コードはこんな感じです。
https://github.com/YuheiNakasaka/yukanya/blob/master/train_vgg.py
100 epoch/総データ量: 6153/サイズ: 64x64と、水増ししすぎてた感があったので半分に減らして再度学習。
結果はこんな感じでデータ量を減らしたのに91%と精度が上昇。
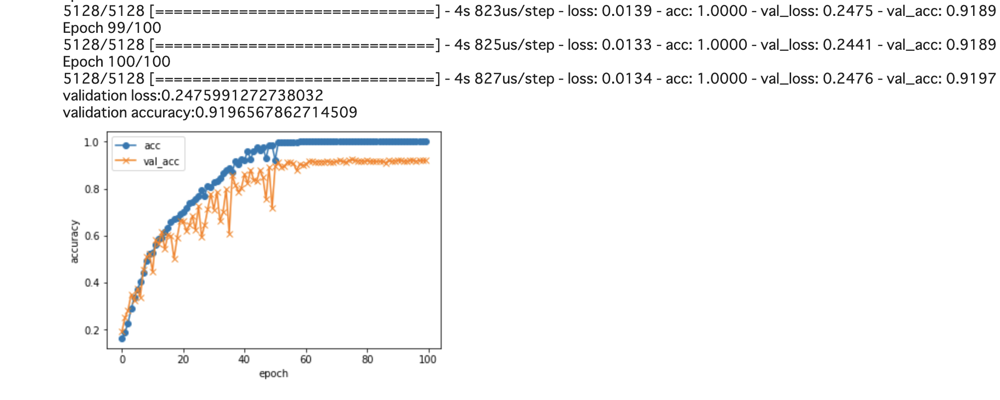
しかもさっきのモデルだとうまく識別できなかった未知の画像(川村文乃ちゃんは宮本佳林ちゃんに似ていると有名)もしっかり分類されました。

Grad Camを使った可視化
ここまででモデルは大方できましたが、では実際に学習済みモデルはメンバーの顔のどこを見て識別しているのか気になりませんか?
その疑問に答えてくれるのがGrad Camという手法です。Grad Camは簡単にいうと、AIがどこを見て画像を判断しているのかを可視化するものです。予測時の判断に大きく影響を与えた(微分係数がデカイ)箇所の特徴を強調します。
Juice=Juiceのメンバーでいうと特に金澤朋子のGuided Grad Camの画像がわかりやすかったです。



彼女は大きな口がチャームポイントなのですが、学習済みモデルもそこをうまく捉えて判断しているようでした。これは人間が金澤朋子を本人であると識別するときとほぼ同様の着眼点なので面白いですね。
Google Colaboratory
ここまでの作業は自前のMacBookProを使っていましたが、ある程度画像が増えてきたりサイズを128x128や256x256のように大きくしていくにつれて次第に学習時間が爆増していきます。
自分の場合は10000枚の128x128サイズの画像をVGG16の転移学習で訓練させようとしたあたりで10時間以上かかることが判明したのでGPUを使うことに決めました。
といってもEC2のGPUインスタンスを立てたりGPUを積んだ物理マシンを購入する必要はなく、Google Colaboratoryを使うと無料で13GBのGPUが使えます。これが本当に恐ろしいほど便利で久しぶりにGoogleのサービスで感動しました。何ができるのかとか制約は以下のQiitaにざっくりまとめられた記事がわかりやすいです。
今の時代、エクセルやスプレッドシートを使って表計算できるのが当たり前になっているようにあと数年でGoogle Colabを使って回帰予測や分類タスクを行えるのがサラリーマンの普通のスキルになっているという未来が見えました。
気になる人はPFN社が無料で公開している下記のGoogle Colabを使ったオンライン講義資料あたりをやってみると良いかもしれないです。 research.preferred.jp
Heroku + Flask + Vue.js + faceapi.jsで簡単にWebサービス化
学習モデルさえできてしまえば、あとはweb上で遊べるようにするだけです。
当初は簡単なCNNのネットワークを使ったモデルを想定していたのでtensorflow-jsを使って全てフロントエンドで完結するぞ!という見立てだったのですが、VGG19に手を出してしまったことで学習済みモデルだけで100MBほどになってしまったので諦めました。
フロントで全て完結しないとなるとサーバー側でモデルを使って予測を行うAPIを作る必要があります。
といっても特に難しいことはいらないのでAPIはPythonのFlaskを使いHeroku上で動かしました。
雰囲気はこんな感じで簡単に立ち上げられます↓
モデルがデカイのとkerasやら何やらをpip installする必要があるので全体でslag sizeは350MBほどになりました。Herokuの無料枠は500MBまでしかUploadできないのでさらに大きな学習済みデータを設置したい場合などは注意が必要です。
Juice=Juice顔診断ではフロントエンドで顔認識をするような作りになっています。というのも、Herokuでface_recognitionを使うのが難しそうだったのと、顔認識に割と時間がかかるのでアクセスが詰まることが予想されたからです。できる限りフロントでできることはフロントで済ませておきたい。
ということでJavascript向けの顔認識ライブラリのfaceapi.jsを利用しました。これまた非常に精度が高い。にも関わらず必要なモデルファイルが6MB程度のサイズ。これなら何とか実用に耐えそうです。
あとはVue.jsを使って適当にフロントをこしらえて、最低限の静的ファイルをServiceWorkerにキャッシュするようにすれば完成です。
類似度判定 - Facenetで特徴量を得て距離を計算する -
ここまではCNNベースで分類した結果を使う作戦でやってきました。
しかしこの手法だと限られたクラスの中でどれに近いかを選択するので、例えば全く顔が似ていないおじさんの写真でもメンバーの誰かには似ているという結果を出してしまいます。それは如何とも許しがたい。
ということでアプローチを変えて、類似度を計算する作戦にします。
類似度を計算するには、それぞれの画像の特徴量を取得してその距離の測れば良さそうです。下記のzozoの例でも画像から特徴抽出を行い、triplet lossという損失関数を計算をしています。
顔画像の場合にはfacenetというモデルがあり、これが特徴量抽出に使えます。
facenetを使って学習データから特徴抽出したらあとはpickleでまとめてherokuにアップロードします。
予測対象の画像がきたら、その画像からも同様にfacenetで特徴抽出して、あとは簡単にユークリッド距離を計算して一番近いものを類似している顔として使うという感じです。
https://github.com/YuheiNakasaka/yukanya-api/blob/master/app.py#L55
これによっておじさんをJuice=Juiceのメンバーに似てない顔として弾くことができました。めでたい🎉

まとめ
- Juice=Juiceの顔診断ができるサイトを作った
- 画像収集/データの整形/簡単なCNNからデータの水増しや転移学習を用いて精度を向上させた
- Google Colab便利すぎる
- 分類タスクだとおじさんがアイドルになってしまう
- facenetを使った特徴量の距離計算で類似度を出すアプローチを取るとおじさんがアイドルにならなくできる
6月頭くらいから初めて土日丸々4日分くらい試行錯誤しました。知識が2,3年前くらいで止まっていて都度学習しながらだったので完成まで思いの外時間がかかってしまいました。
Juice=Juiceは6/18からリーダーの宮崎由加が卒業し新メンバーが2人加入した8人体制になってしまったのでこのサイトはすでにoutdatedなのですが、推しの卒業記念ということで良い勉強にもなったし良かったかなと思います。
それにしてもGoogle Colabはくそ便利で凄かったのでもっとみんな使った方が良いぞという感じでした。
何かある人はブコメか@razokuloverまでどうぞ。